2013/08/06 PowerProducerについて追記
2013/10/06 コンパイルオプションについて追記

今回レビューするのは第4世代Core i7プロセッサの倍率可変モデル Core i7 4770Kです。
4テーマに分かれていますが、担当テーマは「マイクロアーキテクチャの強化」です。
レビューは下記の構成になっています。
1.マイクロアーキテクチャの解説(はじめに)
2.レビュー内容の説明
3.ベンチマーク
4.AVX2、FMA3対応コードによる高速化の検証
4.1インテルコンパイラによる検証(一番頑張った)
4.2Powerproducer 11による検証
それでは、アーキテクチャの解説からはじめます。
マイクロアーキテクチャというのは、CPUの電子回路ハードウェアのことで、具体的にはレジスタやバス、演算器、キャッシュメモリなどの中身や配置、結線の構成を指します。
第4世代core iシリーズのプロセッサで強化されたのは主に下記のポイントです。
・演算処理のためのポート数が6個から8個へ拡充
CPUは処理実行時にリザベーションステーションに命令を蓄積、実行ユニットに命令を出します。実行ユニットは様々なものがあり、一サイクルでポート数分だけの命令をだせます。図に示す通り、ポートごとに命令を出せるユニットが違い、処理が終わるまでそのポートの次の命令は出せないため、特定の処理の連続は実行速度の低下を招きます。有名なハイパースレッディングテクノロジー(HT)は空きポートを使って複数のスレッドの命令を同時実行、仮想的に2コアに見せかける技術だそうです。そう考えるとHTで早くなるアプリと遅くなるアプリがあるのも分かる気がします。
今回増設されたポート7で整数演算を受けもつことによってポート0、1を浮動小数点演算(FP Multiplyなど)に利用しやすくなったとのことです。ほかにもアピールポイントがあり、図中に書いてあります。
Haswellの実行ユニット(Intel発表資料より作成)

・FMAやBMIなどの多用される演算に対応した拡張命令、演算器の追加
ポートとともに演算器も追加されています。演算器としてはFMAユニット、新拡張命令としてはAVX2とFMA3の二つになります。AVX2では整数の256bitベクトル演算命令を代表とした、ベクトル演算の増加、FMA3ではAVX2と同様のベクトル計算においてFMAと言う操作を1命令で行うようになっています。
おそらく上図のFPのユニットがAVXの命令を実行すると思われますが、調べてもよくわかりませんでした。また、AVX2は命令セットの拡張だけでマイクロアーキテクチャの拡張ではないかもしれません。
以上がHaswellで大きく変わったマイクロアーキテクチャです。
以下の項目は従来からあるユニットの拡大です。
・L1、L2キャッシュ帯域の倍増
L1、L2キャッシュはメモリよりも近くにある記憶域で、ここに保存した変数を利用してCPUは計算します。メモリアクセスにより実行速度が遅くなりのは有名ですが、L1、L2キャッシュ間、L1からレジスタ等への読み込みも高速化して、実行速度の向上を行っています。
・L2 TLB のエントリ数増加
物理アドレス-仮想アドレスの変換を補助するもので、キャッシュミスの際のメモリアクセスの効率化により実行速度の高速化を行います。
・リオーダバッファ、リザベーションステーションのエントリ数増加
リオーダバッファは演算結果を蓄えておく場所で、リザベーションステーションと併せて、実行可能な命令、データを演算器に効率よく回すことにより、実行速度が高速化します。
・演算に利用する値を格納する物理レジスタユニットの増加
レジスタの増加により演算時のデータアクセスが減少して実行速度が増加するものと思われます。
以上がCPUマイクロアーキテクチャの強化ポイントの主要部分です。
これに加えてHaswellではGPU部分も相当強化されているようです。4770Kに搭載されているのはGPUの4つのグレードの中で下から二番目のGT2に属するIntel HD Graphic 4600ですので、真価は今後出る新CPUで発揮されるのだと思われます。
14%の高速化とは???
レビューの副題に14%の高速化というのがあり、出典があるのかと思って調べたところ、CinebenchR11.5で14%高速化、Visual Studio 10 Compile benchmark(何かは不明) で14%高速化というのがありました。
浮動小数点演算器の増加などで実行速度はピークで2倍という文献もありましたが、とにかく速くなったことは間違いないでしょう。

レビュー内容としては応募時に書いた通りにします。
具体的には定格クロックにおける下記の内容になります。
応募時にはFMA3はAVX2の一部だと勘違いしていたので修正しています。
・各種ベンチマークの比較(Cinebench,SuperPi)
・AVX2、FMA3の有効性検証
i.AVX2、FMA3対応インテルコンパイラを利用したコード実行速度の検証
ii.AVX2対応動画編集ソフトPowerDirector11によるエンコード速度の検証
比較できるところは第3世代プロセッサCore i7 3770Kと比較しながら進めていきます。
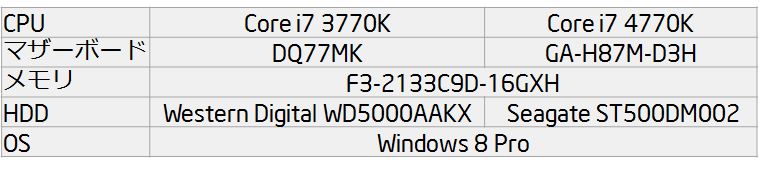
マシン構成
双方定格運用ということで、OC機能なしのマザーボードでやります。HDDを合わせていませんが、HDDアクセスに支配される検証はしないと思われるので、誤差だろうと高をくくっています。

各種ベンチマークは先行例が数多くありますので、構成の妥当性検証と言う意味もこめて実行してみます。
実行したのはウィンドウズエクスペリエンスインデックス、Cinebench R11.5、Superπです。今更Superπかというところもありますが、旧来のアプリという意味では貴重だと私は思っています。
まずはエクスペリエンスインデックスです。グラフィックは内蔵グラフィックです。4770Kではプロセッサスコアが8.1となっており、着実に進化しているとわかります。グラフィックはデスクトップグラフィックス面での伸びが大きく、ひょっとしたら安いグラボより良いかもしれません。

Super-π838万桁とCinebench 11.5は下記のとおりです。
CinebenchはDOS-Vパワーレポート等の値とおおむね一致しているので、正常に機能していると思われます。
どちらも特に新命令セットを使いませんが、高速化しています。


AVX2、FMA3命令セットはSIMD演算の一種で、256bitのデータを一命令で演算することができます。SIMD演算というのは1回の命令で複数の演算を同時に行うものです。たとえばAVX2ではint型、float型を8つ同時に計算できますので、図のように配列の足し算では8つの足し算を一回でやることができます。並列化と違ってCPUコアは1つで行うのでCPU使用率は同じになります。


インテル® C++ コンパイラー XE 13.0を使って検証を行いたいと思います。Windows版と無償のLinux版がありますが、Visual Studioと統合できるWindows版体験版を使いました。
実はVisual Studio 2012でもAVX2対応だったのは後から気づきました。
基本的にAVXを使う場合はC++かFortranでコードを書くようです。
■コンパイルオプションについて(13/07/27追記 13/09/16修正)
インテルコンパイラにはコンパイル時に実行ファイルを勝手に高速化したり並列化してくれる機能があり、それらを明示的に利用する場合にはコンパイルオプションを付けます。
今回はVisualStudioで作成したVisual C++プロジェクトをIntel C++のプロジェクトに変換したので、下記のようにずらずらとオプションが付いていました。
/GS /W3 /Gy /Zc:wchar_t /Zi /O2 /Fd"Release\vc110.pdb" /fp:precise /D "WIN32" /D "NDEBUG" /D "_CONSOLE" /D "_UNICODE" /D "UNICODE" /Zc:forScope /Gd /MD /Fa"Release\" /EHsc /nologo /Fo"Release\" /Fp"Release\FMATest.pch" /Qvec-
沢山ありますが、実行速度に聞いてくるのは /O2と /fp:precise /Gy程度だと思われます。
特に浮動小数点演算の精度を示すfp:preciseが効くようで、Visual C++だとデフォルトは精度の高いfp:preciseなのですが、高速が売りのインテルコンパイラではfp:fastがデフォルトのようです。そのため、コメントに記載頂いたsorrowさんの実行結果と異なった結果になったようです。fp:fastにした結果はまた追記予定です。→下の方に追記しました。2013/10/06

■前提知識の解説
AVX2に対応したC++コードでは、整数型、浮動小数点型の数値を256bitひとまとめにしたデータ型を使います。
AVX対応のデータ型は単精度浮動小数点の__m256f型、倍精度浮動小数点の__m256型、整数型の__m256i型の三種類です。それぞれfloat型、double型、int型の変数に対応しています。これらのデータ型はパックドデータ型と呼ばれ、一つで256ビット分の複数の変数を保持します。ポインタだったりというところは割愛です。

演算命令も専用のものになっており、長い名前の関数になっています。FMA3も一緒に書いています。下図はdouble型に対応する関数リストです。

■検証用プログラム
プログラムは1000要素の配列の要素の2乗を別の配列に入れていくものです。図はdouble型用のループ部分です。AVX型だと内側のループ回数が4分の1になっています。これは先ほどのとおり一回で複数要素を計算するためです。ind,outdが通常のスカラー配列、ind2、outd2がAVX型の配列です。

double、float、intの3つの型でやってみます。1000要素の足し算ではあっという間に終わるので、それを20000000回ループ(コード中のNLOOP)させるようにしています。
また、整数に関しては比較のためにAVXより前のSIMD命令のSSEでも計算しています。SSEはAVXの半分の量(128bit)の計算を一命令で行う命令です。
■実行結果
結果は下記のとおりです。確認のために1000要素目の結果(999x999=9998001)を表示しています。
最初の行は実行した演算とループ回数を示しています。
2行目以降が結果で、「with AVX」がAVXを利用、「scalar」がベクトル化しない計算、「with AVX2」がAVX2の整数演算です。AVX2は3770Kでは使えないので、3770Kにはありません。各行末が実行時間となります。
全体として高速化していること、これまでSSEでしかできなかった整数のベクトル演算がAVX2によって2倍程度高速化していることがわかります。


■前提知識の解説
FMA3はAVX等のパックドデータのFMAと呼ばれる計算を1命令で行う命令セットで、対応したFMAユニットがHaswellマイクロアーキテクチャから追加されています。
FMAというのはd = a × b ± cというような掛け算と足し引き算を組み合わせたもので、通常はaとbの掛算、cの足し算の2回で行います。2回に分けると誤差が発生することもあり、FMAユニットがあると高速化に加えて、一度で計算するために誤差が減るという利点があるそうです。
■検証用プログラム
今回はFMA3でどれくらい高速化するかを見てみます。計算はdouble型で、1000要素の配列を3つ用意、a x b + cの計算を各要素で行うものです。スカラー、AVX、FMA3の3パターンでやってみます。

■実行結果
実行結果です。AVX2と同様に1行目が計算内容、2行目以降が実行結果です。
配列aとbのi番要素は2×i、配列cのi番要素は3×iとしました。結果確認用に999番目の計算(1998×1998+2997=3995001)を表示しています。各行末が実行時間です。
全体として4770Kで速度向上していること、AVXで速度向上していることがわかります。FMA3は同じ処理のAVXよりも10%程度速度向上が見られます。アプリで対応する価値はあると思います。

■コンパイルオプションによる違い(13/09/16追記 10/06結果追加)
浮動小数点演算の取り扱いに影響する/fp:fastと/fp:preciseの違い、sorrowさんによるキャストを用いないで明示的なレジスタへの割り当てを行うコードと記事末尾に記載したこちらのコードとの比較を行います。
最適化オプションはデフォルトの/O2だけです。上のコードでつけていた/Qvec-は使っていません。
結果は以下の通りです。
キャストなしというのがsorrowさんの記事に記載されているコード、キャストありが本記事の末尾のコードです。
sorrowさんのコードをfp:fastでコンパイルした結果はsorrowさんの記事に近い結果なのでコンパイラの条件はあわせられているようです。
fp:fastからfp:preciseにするとキャストなしのコードでは大きな差が出ていますが、本記事のコードではそこまで変化はありませんでした。キャストありだとFMA3がpreciseのほうが速くなっています。
スカラーの計算が前回と違って、10秒かからなくなっているのもちょっとわかりません。前回利用した実行ファイルではやはり10秒かかるのでオプションの見落としがあるかもしれません。
色々怪しいところがあるのですが、キャストの有無だけなのか、コードの書き方がわるいのか(単純なのでそこまで差はでないと思うのですが、、、)。
とりあえず結果はこのようになりましたというところで、ひとまず終了したいと思います。

■ベクトル化オプションについて (スカラー演算速度の考察)
今回/Qvec-を付けなかったことで、FMAの効果検証時と違ったスカラー演算速度になりました。
そこで、スカラー演算速度の変化についてベクトル化オプションの違いから考察します。
コンパイルオプションを指定するときにベクトル化、AVX2のSIMD利用に関しては以下のオプションがあります。
ベクトル化 /O2(ベクトル化あり) /O3(ベクトル化あり) /Qvec-(ベクトル化オフ) など
SIMD /QxAVX(ベクトル化にAVX命令を利用) /QxCORE-AVX2(ベクトル化にAVX2命令を利用) など
この中で、最初にやったスカラー演算に10秒かかる条件にするには/Qvec-を付けた条件、浮動小数点精度の検証に使ったスカラー演算に5秒かかる条件では/O2のみ(デフォルト)、/QxAVXなどを使うと、さらに高速なAVXベクトル化になり、これだと3秒を切ります。参考にさせていただいたsorrowさんの記事にAVXの自動ベクトル化がいかに優れているかが記載されています。
キャストと明示的な読み込みの差はまだ謎です。
■アセンブラコードから考える
まず、sorrowさんのコードがfastとpreciseで2倍程度と劇的に高速化していたので、その原因を考えます。
アセンブラコードを出力する/FAのオプションを使って、FMAの部分についてどのようにコンパイラが解釈したかを検証しました。
fp:fastとfp:preciseを並べてみます。(大きいので別窓でひらいてください。)

並べてみると、b1.41とb1.42のループの順序が逆になっていることが分かります。
fp:fastの場合、b1.41の最後の行に、ジャンプを示す「jb .B1.41」があることから、b1.41の中だけを2000万回繰り返しているようです。
fp:preciseの場合、この命令はb1.42に行っていて、最後が「jb .B1.40」になっているため、.B1.40と.B1.41を含むループを2000万回繰り返すと思われます。
fp:fastだとfma命令を含むループが1回しか出てこないため、fp:preciseとそもそもやっていることが変わっているように思われます。
結果は同じですが、fp:fastだとFMAの回数が変わっているように見えます。良く高速化できているといえばそうですが、コードに忠実な命令はfp:preciseなので、実行速度の検証としてはfp:preciseが妥当だと考えられます。
まずfma演算の部分はsorrowさんのコードの.B1.41、本記事のコードの.B1.44となります。
つぎにfp:preciseで比較すると、本記事のコードが10%以上遅くなっています。その差異の原因について二つのアセンブラコードを比較して考えてみました。(大きいので別窓で開いてください。)

比較すると、本記事のコードではジャンプ(jb、jl)以外の命令で7行、sorrowさんのコードでは6行になっています。
本記事のコードでは「inc ecx」が入っています。
inc ecxはループ回数を保持しているecxレジスタの値を1増やす命令で、「cmp ecx,250」のところでループ上限の250回と比較するために使っています。
sorrowさんのコードでは数値のアドレスか何かを確保しているeaxを使うようになっていて、回数と変数のインデックスを共用しているようです。
また、それ以外の点として、sorrowさんのB1.40、本記事のB1.43で本記事の方がxorが一つ多くなっています。つまり、本記事のほうが全体として命令数が多いです。
どうしてsorrowさんとおなじアセンブラコードにならないのかということですが、ソース内での差異として、以下の2点がありました。
1.配列確保のところ
2.ループ内でレジスタに配置するところ
ベクトル化のレポート(下画像)をみると、これらの違いから、sorrowさんのコードではFMA、AVX2計算を繰り返すfor文がmemsetかmemcpyに変化できて、それにより高速化できているようです。

ここまででわかったこととして、FMA、AVX2を直接つかう以外の要因が実行速度の差の原因の一つだというところです。
これがsorrowさんのコードとの速度差を示すとしても、FMAとAVX2での差が本記事では出て、sorrowさんのコードでは出ない理由はまだよくわかりません。

秋葉原のイベントでもデモ機が用意されていたCyberlinkのPowerDirector11を使って新マイクロアーキテクチャが実際のアプリでどの程度効果を発揮するかを見てみます。
検証は2分30秒程度の1080pの動画をH264、1080pにエンコードしてやります。
フィルターは30秒x4種類(TV シミュレーター、モザイク、ウェーブ、ガウス状のぼかし)かけています。あまり詳しくないので、結果だけの議論になります。

うーん、、、確かに速くはなっていますが、AVX2に対応していない感じの高速化具合です。
ひとまずここまでで、AVX2に対応しているかCyberlinkに問い合わせて後日追記しようと思います。
2013/08/06追記
Cyberlinkに問い合わせたところ、AVX2に対応するのは次期バージョンからということでした。雑誌などでPower Producer11での高速化が書いてあったので対応していると思い込んでいました。

今回のレビューでは新マイクロアーキテクチャの調査、検証を行いました。
ベンチマークでは従来のアプリでも、同周波数で高速化することが確認できました。
インテルコンパイラーによる検証はAVXコードの書き方を調べるところからだったのですが、なんとか効果が見える形に持って行けたかと思います。自分でやってみて、改めてインテルのテクノロジーの凄さを体感できました。
ちなみにインテルコンパイラーは今回やったような複雑な命令を書かなくても、勝手にAVX2対応のベクトル化をやってくれます。実際その方が速いことも多いので、プログラミングの専門家でなければ「自動ベクトル化」という機能を活用するだけで簡単にAVX2の恩恵を受けられます。
Windows版インテルコンパイラーは非常に高価なので、Windows環境でAVX2やFMA3を使うにはMicrosoft Visual C++が現実的かもしれません。VC++も自動ベクトル化があったような気がしますし。
エンコードは完全に付け焼刃の知識で、いまいちの結果でした。後日AVX2対応状況がわかったら再度挑戦してみようと思います。
今回試した内容だけでも、14%の高速化という一言で片づけられない変化がHaswellアーキテクチャではありました。 今後新アーキテクチャに合わせてプログラム最適化されることで、ベンチマークだけでなく、様々な実用的メリットが見えてくるのではないかと期待します。
詳しいわけではなく、調べたものを自分なりの理解で書いているので、見当違いのところがあるかもしれません。ご容赦くださるとともに、ご指摘いただければ幸いです。
FMA3の検証用コード:
#include <stdio.h>
#include "immintrin.h"
#include "iostream"
#include "math.h"
#include "time.h"
#define SZ 1000
#define NLOOP 20000000
double clock_it(void) { clock_t start; double duration;
start = clock(); duration = (double)(start) / CLOCKS_PER_SEC; return duration; }
int main(void){
double execTime = 0.0;
double startTime,
endTime;
std::cout<<"Multiply a["<<SZ<<"] and b["<<SZ<<"] and Add c["<<SZ<<"] for "<<NLOOP<<"times"<<std::endl;
//double型
//in, outをアライメントして確保 _declspec(align(32)) double ind1[SZ], ind2[SZ],ind3[SZ] ,outd[SZ];
//in にデータをセットする処理
for(int i=0;i<SZ;i++){ ind1[i]=2*i; ind2[i]=2*i; ind3[i]=3*i; }
//AVX型に割り当て
__m256d *ind1vec = (__m256d *) ind1, *outdvec = (__m256d *) outd; __m256d *ind2vec = (__m256d *) ind2, *ind3vec = (__m256d *) ind3;
startTime = clock_it();
//AVXを用いず計算
//NLOOP回FMA処理
for(int iloop=0;iloop<NLOOP;iloop++){ for(int i=0;i<SZ;i++) outd[i] = ind1[i]*ind2[i]+ind3[i]; }
endTime = clock_it();
std::cout<<"double scalar "<<ind1[SZ-1]<<" "<<outd[SZ-1]<<" execution time is "<<endTime-startTime<<"s"<<std::endl;
startTime = clock_it();
//AVXを用いて計算
//NLOOP回FMA処理
for(int iloop=0;iloop<NLOOP;iloop++){ for(int i=0;i<SZ/4;i++) outdvec[i]= _mm256_add_pd(_mm256_mul_pd(ind1vec[i],ind2vec[i]),ind3vec[i]); } endTime = clock_it();
std::cout<<"double with AVX "<<ind1[SZ-1]<<" "<<outd[SZ-1]<<" execution time is "<<endTime-startTime<<"s"<<std::endl;
startTime = clock_it();
//FMA3を用いて計算
//NLOOP回FMA処理
for(int iloop=0;iloop<NLOOP;iloop++){ for(int i=0;i<SZ/4;i++) outdvec[i] =_mm256_fmadd_pd(ind1vec[i],ind2vec[i],ind3vec[i]); }
endTime = clock_it();
std::cout<<"double with FMA3 "<<ind1[SZ-1]<<" "<<outd[SZ-1]<<" execution time is "<<endTime-startTime<<"s"<<std::endl;
return 0;
}
sorrowさん
2013/07/07
素晴らしいです。
kilifさん
2013/07/07
ありがとうございます。
単純でも実際にコードを書いてみたほうが、自分にとって分かりやすいと思いやってみました。
sorrowさん
2013/07/14
スクリプト、有難うございます。そのまま走らせてみました。
コンパイラの自動ベクトル化ありと(なし)で、
scalar: 2.957s (5.43s)
AVX: 3.467s (3.57s)
FMA3: 3.271s (3.283s)
こんな感じです。実はkilifさんにご指摘頂いた自動ベクトル化は私も考えていたのですが、オプション指定を間違っていて(/QVec-と大文字にしていました)良く分からない結果だなと思っていました。有難うございました。
kilifさんのスクリプトでも自動ベクトル化ありだとスカラーが一番速くなりますが、私のスクリプトでも同じで、スカラーが一番速くなります(私のレビューの方にも自動ベクトル化を抑制したベンチマークを加えた図を上げておきました)。コンパイラによるSIMD化がSSEまたはAVX命令セットの何を使うかによるのかもしれません。
私の実行環境は、32 bit Windows 7, Visual Studio 2012 Express, Intel C++ Composer XE 2013評価版で、
Intel Parallel Studio XE 2013>Command Prompt>インテル(R)コンパイラー 13.1 Update 3>IA-32 Visual Studio 2012モード
を使っています。
スカラーの実行時間がkilifさんのマシンと違うのは、他にもSIMD関連の隠れたスイッチがあるのかもしれませんね。興味は尽きません。
kilifさん
2013/07/17
こちらこそご指摘、クロスチェックありがとうございます。
こちらの計算ではVisualStudioからのコンパイルになっており、VisualC++コンパイラのオプションに引きずられてコンパイルオプションがいくつかついていました。
大きく効いていたのが浮動小数点演算精度オプションのfp:preciseで、インテルはデフォルトでfp:fastになっているためsorrowさんの計算だと速かったようです。
こちらもコンパイルオプションを変えたものを追加しようと思います。
sorrowさん
2013/10/06
コンパイラのfpオプションの比較、とても面白いです。生成されたコードはpreciseの方は素直でそのままですが、興味深いのはfastの方です。
まず、ベクトルデータの一部のみを順番に計算している(.B1.42)ということと、20000000回ループしているのはメモリ格納動作のみで(.B1.41)、FMAは1回しか実行してない(.B1.40)ようです。コンパイラが賢いと言うか、無駄を省いてくれているということでしょうか。しかも、vmovntpd (_mm256_stream_pd)はキャッシュを介さない高速ロードになっています。
ベンチマークの目的としては、kilifさんのご指摘の通り、preciseオプションでFMAをループさせないと意味ないですね。最終的には、明示的にロードした場合、FMAとAVX2がスカラーの2倍程度高速になるということで、これがHaswellの実力を表しているように思います。
いろいろ挙動不審と思われた点がコンパイラの動きによるものであることが分かって、すっきりしました。ベンチマークの面からはコンパイラの「おせっかい」とも言えますが、今のコンパイラってすごいんだなと思いました。
kilifさん
2013/10/06
コメントありがとうございます。
アセンブラコードをみるのは初めてなので、どれくらい速度に効くのかがわかりませんが、明示的にロードしたのが今回の検証法ではFMA、AVX2の実力というところで間違いないと思います。
今回コンパイラでやればよくわかるようになると思いましたが、
逆にコンパイラの動きが読めず振り回されてしまったところがあるので、アセンブラコードで検証できるのが理想なんでしょうか。
私のレベルだと実用上は下手に最適化に手を出すより自動ベクトル化に頼ったほうが良さそうという感触です。